


学习教程来自:【技术美术百人计划】图形 3.4 延迟渲染管线介绍
延迟渲染
渲染路径 Rendering Path
光照的实现方式
渲染使用的光照流程
渲染方式
前向渲染 Forward Rendering
待渲染几何体->顶点着色器->片元着色器->渲染目标
每个顶点、片元执行着色器代码时,都需要读取所有的光照信息(包括很远的光源)
光源的处理规则参考这篇文章 Real-Time Rendering笔记(6):正向渲染和延迟渲染
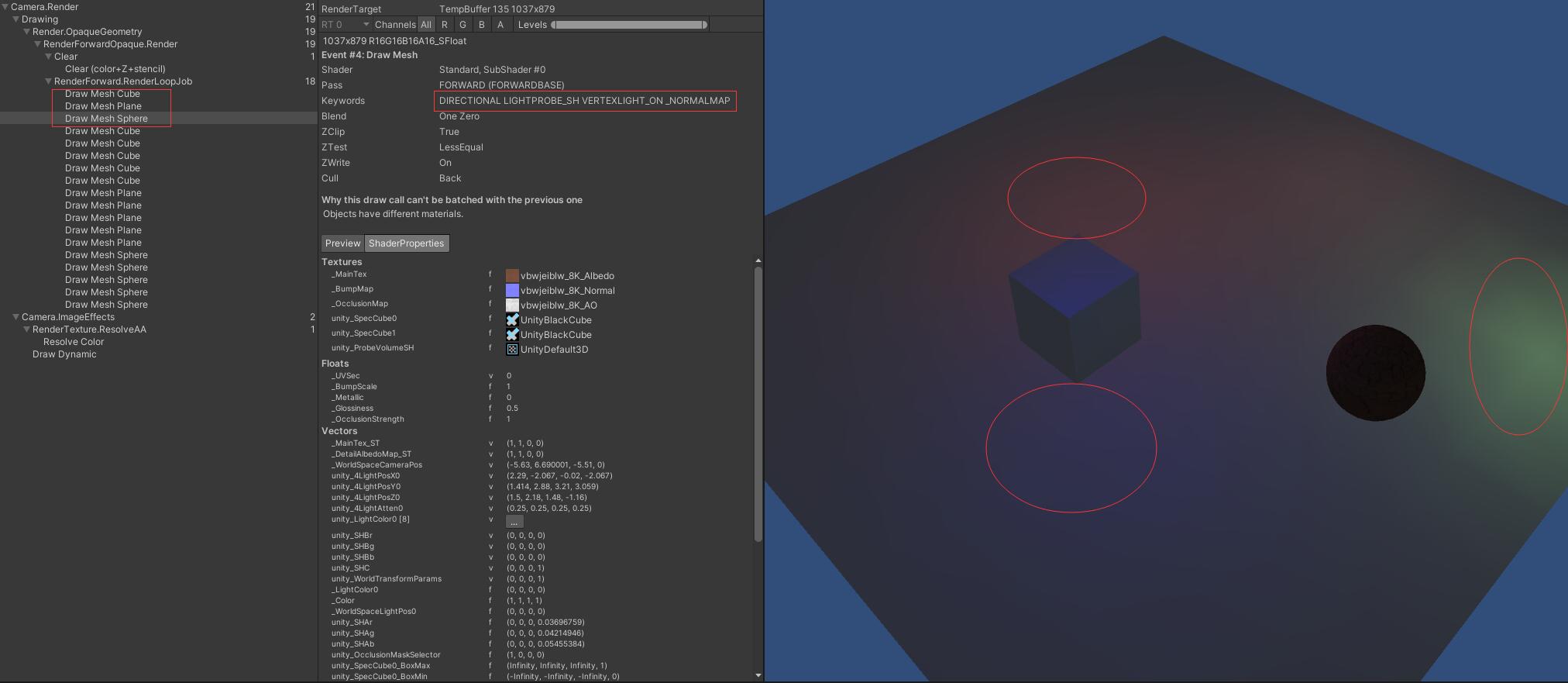
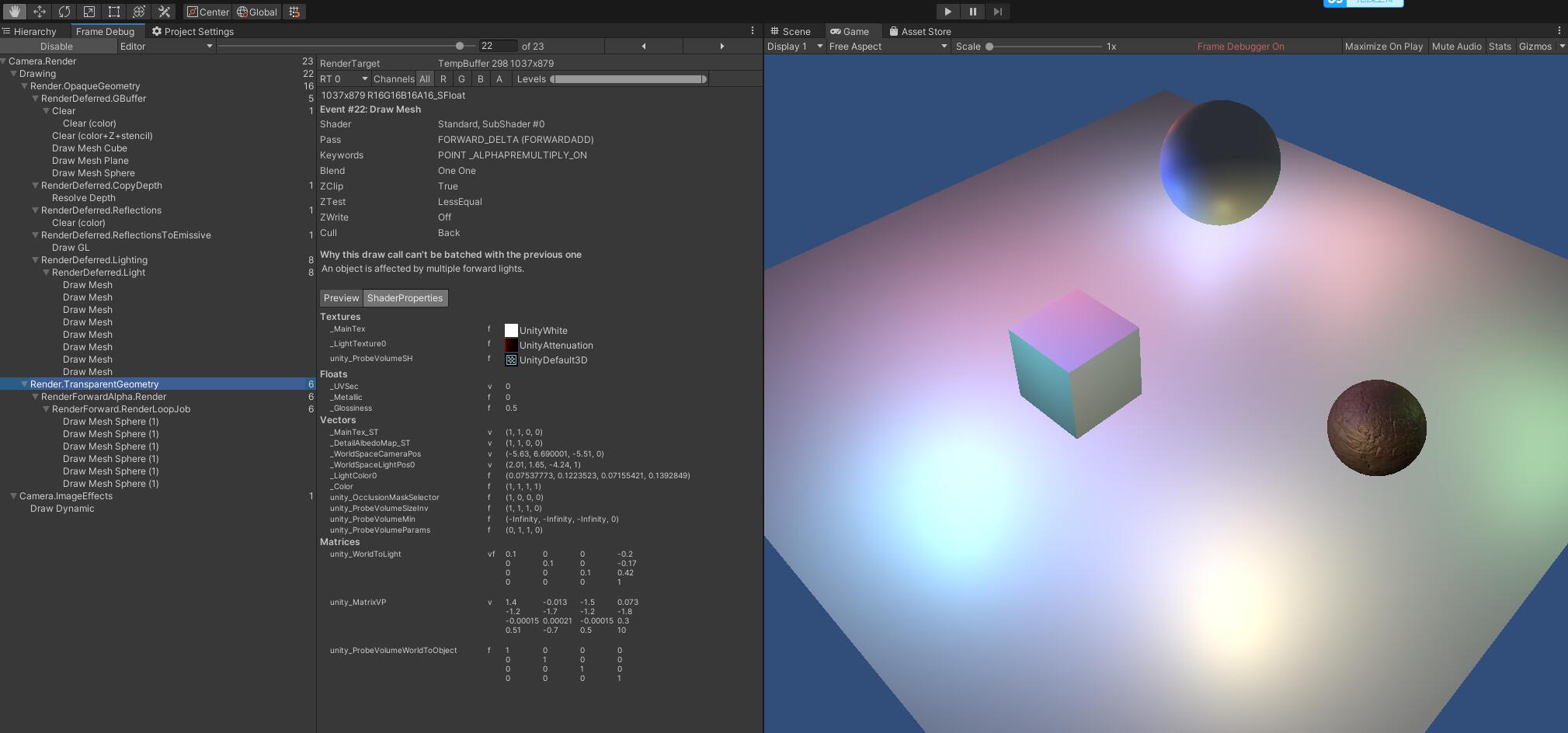
Unity中,开启Frame Debug,以Plane着色为例进行分析
首先,可以看到3个物体的渲染,分别先进行了顶点的光源的绘制(一次一个物体,由于Quality Setting里的Pixel Light Count中的数量设置为5,所以8个光源中,有3个光源作为了顶点光照、球面调谐光照/SH)
详细信息中是如下标注的,是顶点和SH都有还是其他情况存疑?
Standard, SubShader #0
DIRECTIONAL LIGHTPROBE_SH VERTEXLIGHT_ON _NORMALMAP
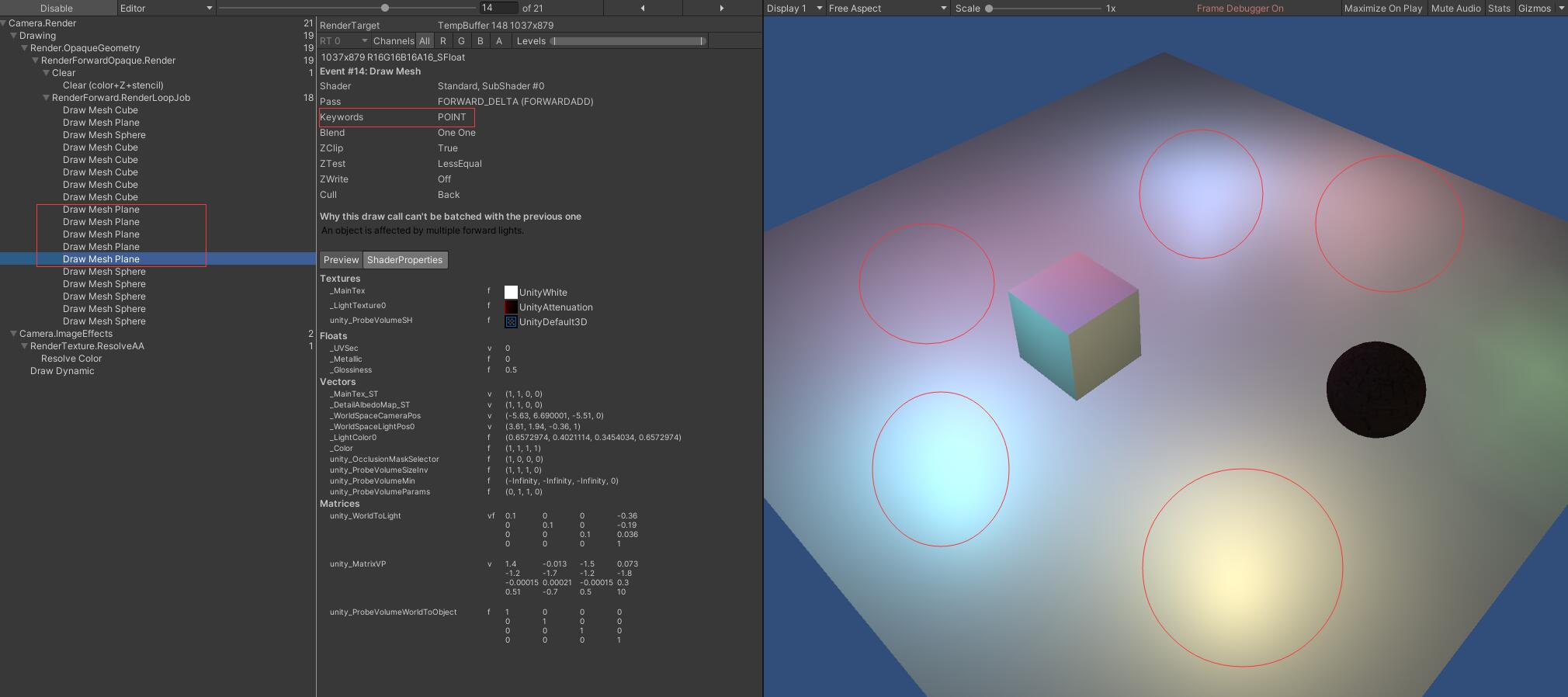
Standard, SubShader #0 POINT
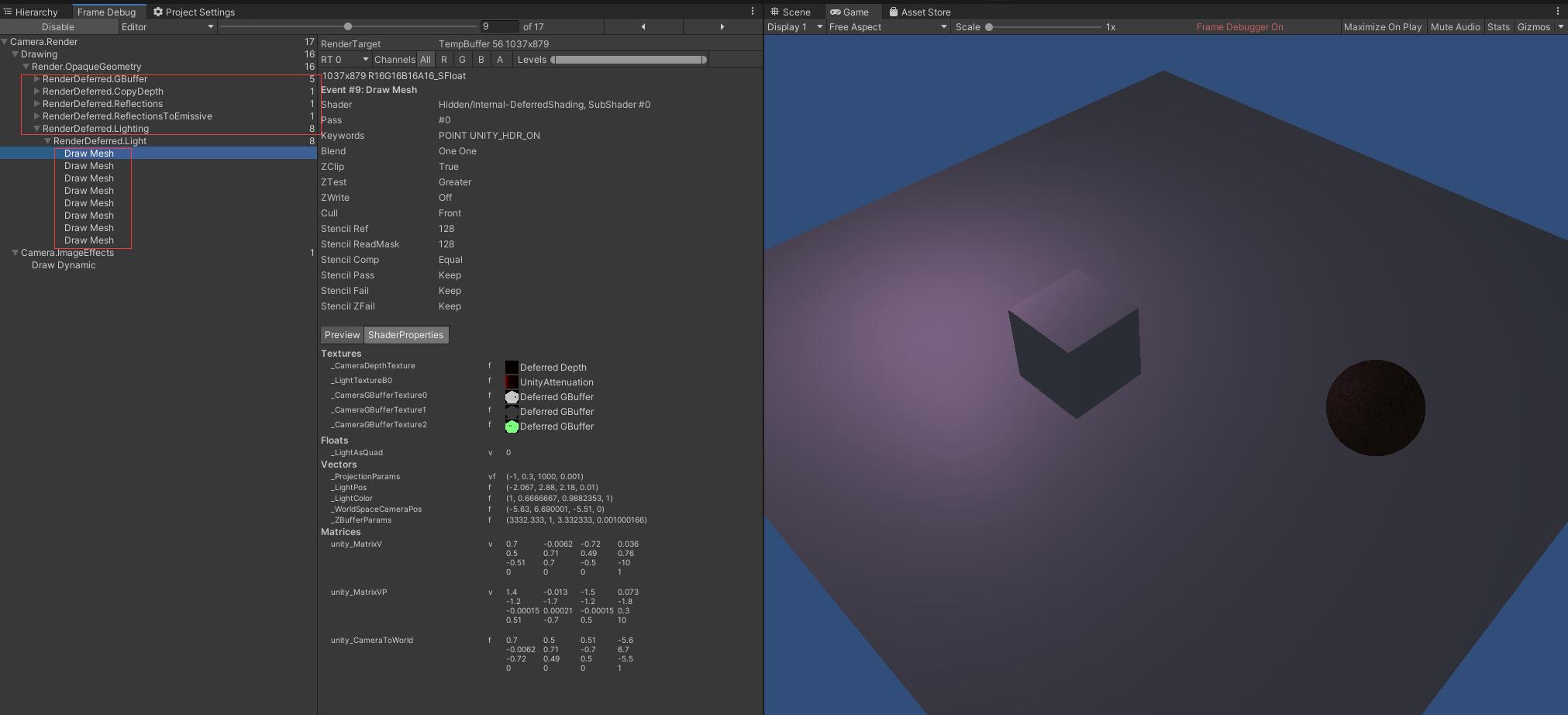
就是先将信息写进G-buffer中,再进行光照计算,这样就只需要进行 光照次数(8次) 的计算
一共2个Pass:1. 将信息绘制进G-buffer/RT中。2. 对这些信息进行光照计算(相当于一个2D的后处理)。
同一场景下的性能对比

剔除的方法:先将场景下所有物体的信息都绘制到一张Render Texture上,保存在G-buffer中,绘制的过程中利用深度信息剔除掉了被遮挡的部分
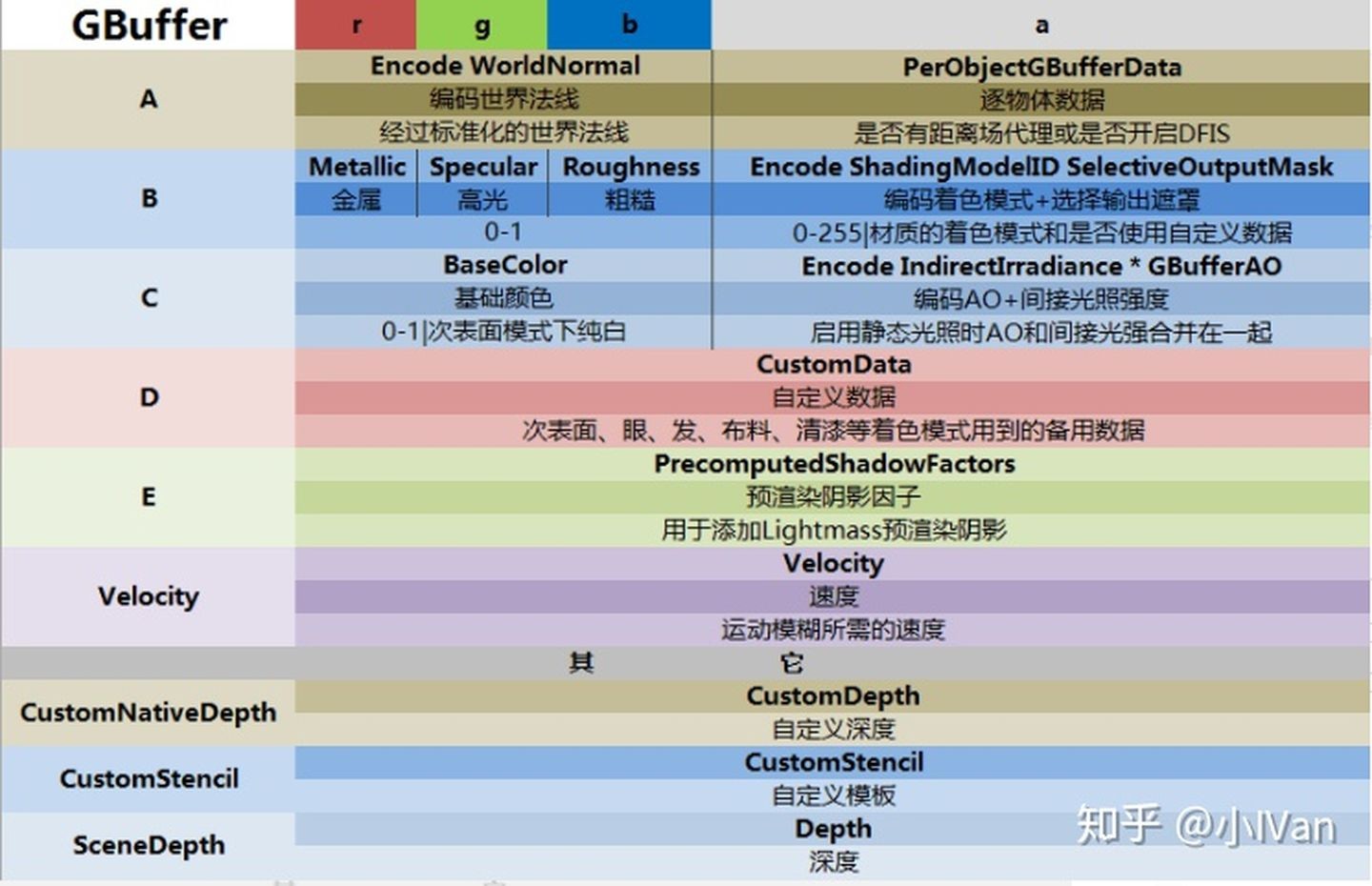
关于UE中的RT信息,目前我接触到的有2种方式查看,一种是系统自带的视图切换,另一种是RenderDoc,类似于Unity中的Debug Frame
RenderDoc的安装参考使用RenderDoc来调试UE渲染(转载)

透明的物体在Unity中采用前向渲染的方式,无论相机的渲染方式是前向还是延迟渲染,透明物体放在最后处理
如图所示共绘制了6次(1顶点光照+球协光照 5像素光照)
不同渲染路径的特性
- 后处理方式不同:前向渲染不过需要深度信息进行后处理,需要单独渲染出一张深度图;延迟渲染可以直接从G-buffer中取得(因为不会及时清理掉,所以延迟渲染会有显存带宽占用高的问题)。
- 着色计算不同:延迟渲染的光照计算统一在LightPass中计算,所以只能计算一种光照模型。切换光照模型就需要切换Pass。
- 抗锯齿方式不同。
不同渲染路径的优劣
前向渲染的缺点
| 前向渲染的缺点 | 前向渲染的优点 | 延迟渲染的缺点 | 延迟渲染的优点 |
|---|---|---|---|
| 光源数量对计算复杂度影响大 | 支持半透明渲染 | 对MSAA支持不友好 | 光源数量多时优势明显 |
| 获取深度等数据需要额外计算 | 支持多个光照Pass(不同的LightModel) | 透明物体渲染存在问题 | 只渲染可见像素节省了计算量 |
| 支持自定义光照 | 显存占用高 | 对后处理支持良好 | |
| 比前向渲染更清晰(视情况) |
其他
以下内容大部分复述自片头的PPT
Unity中延迟渲染的设置
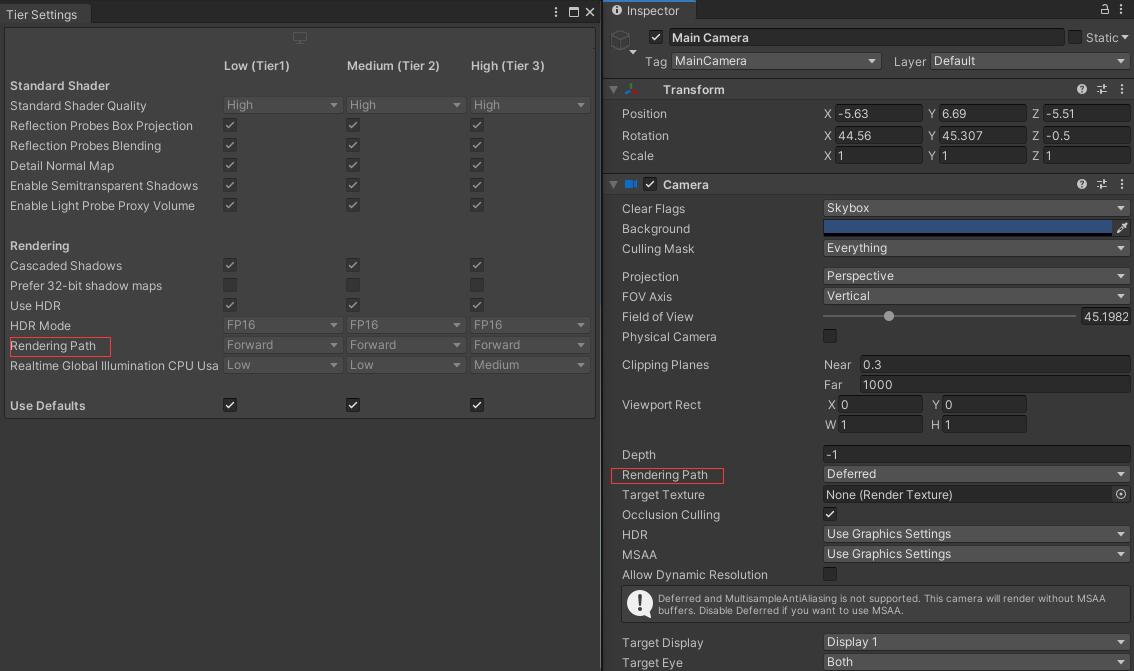
延迟渲染移动端优化
- TBDR:提出于SIGGRAPH 2010,基于分块的方式降低带宽、内存占用
- TBDR:提出于PowerVR基于手机GPU的TBR架构,做一些可见性测试来减少OverDraw
其他的渲染路径
- 延迟光照/Light Pre-Pass/Deffered Lighting:不同于延迟渲染,使用了更少的G-buffer信息(减少了带宽),支持多种光照
- Forward+/Tiled Forward Rendering/分块正向渲染:通过分块索引的方式,以及深度和法线信息,拿到需要进行光照计算的片元进行计算,强制使用preZ。好处:减少带宽,支持大规模光源,MSAA和透明渲染正常
- 群组渲染/Clustered Rendering:又分为Clustered Forward Rendering和Clustered Deferred Rendering。前者在Forward+ Rendering的基础上又沿着相机深度的方向切了很多片。Clustered Forward Rendering也即是在Tiled Deferred Rendering的基础上又沿着相机深度的方向上进行了切片。
MSAA问题
MSAA多重采样反走样(渲染更多的像素再去合并),但在延迟渲染中的数据,已经被存储到了RT中,没有进行多重的计算,虽然三角形的边缘仍然可以受益于MSAA,但是RT中的数据仍旧会走样。你必须采用后处理的方式去进行反走样了。
Unity不同Path下光源Shader的编写
使用LightMode tag,详见官方文档
PreZ/Zprepass
用一个Pass只算深度
用途举例:大规模草的Pre计算、透明排序、延迟渲染的片元剔除、URP中的深度贴图
深度图和深度数据的不同:前者用于记录数据并便于传递,自动进行的。后者当深度图失效时,作为一种手动的代替方案。
一些现状
Unity URP新管线不支持延迟渲染
UE默认为延迟渲染
Unity中自定义延迟渲染的Shader
作业
延迟渲染管线的缺点:
来自PPT中:
| 前向渲染的缺点 | 前向渲染的优点 | 延迟渲染的缺点 | 延迟渲染的优点 |
|---|---|---|---|
| 光源数量对计算复杂度影响大 | 支持半透明渲染 | 对MSAA支持不友好 | 光源数量多时优势明显 |
| 获取深度等数据需要额外计算 | 支持多个光照Pass(不同的LightModel) | 透明物体渲染存在问题 | 只渲染可见像素节省了计算量 |
| 支持自定义光照 | 显存占用高 | 对后处理支持良好 | |
| 比前向渲染更清晰(视情况) |
来自RTR4 20. Efficient Shading 20.1. Deferred Shading中:
缺点:
- Typically three to five render targets are used as G-buffers, but systems have gone as high as eight [134]. Having more targets uses more bandwidth, which increases the chance that this buffer is the bottleneck.(更多render target作为G-buffer,占用了更多的带宽,导致G-buffer可能成为性能的瓶颈)
- G-buffer video memory requirements can be significant, as can the related bandwidth costs in repeatedly accessing these buffers [856,927,1766].(显存要求高,同时频繁读取buffer导致带宽消耗大)
- Transparency is not supported in a basic deferred shading system, sincewe can store only one surface per pixel.(由于我们每个像素只能存储一个平面,所以基础的延迟渲染不支持透明渲染)
- Forward techniques need to store only N depth and color samples per pixel for N×MSAA. Deferred shading could store all N samples per element in the G-buffers to perform antialiasing, but the increases in memory cost, fill rate, and computation make this approach expensive [1420]. (前向渲染只需要存储N层深度的样本用做MSAA,但是延迟渲染需要对每个RT都存储N层,这样的消耗是巨大的)
可能的解决思路:
- We can mitigate these costs by storing lower-precisionvalues or compressing the data [1680,1809].(可以通过压缩来减少显存和带宽消耗)
- While it is possible to now store lists of transparent surfaces for pixels [1575] and use a pure deferred approach, the norm is to mix deferred and forward shading as desired for transparency and other effects [1680].(通过混合延迟渲染和正向渲染的方式可以一定程度上解决透明渲染问题)
- Shishkovtsov [1631] uses an edge detection method for approximating edge coverage computations. Other morphological post-processing methods for antialiasing (Section 5.4.2) can also be used [1387], as well as temporal antialiasing. Several deferred MSAA methods avoid computing the shade for every sample by detecting which pixels or tiles have edges in them [43,990,1064,1299,1764]. (3个思路去支持MSAA:边缘检测作为反走样的方式、后处理、仅保存需要进行MSAA的像素或块)Their technique performs adepth and normal geometry prepass and groups similar subsamples together. They then generate G-buffers and perform a statistical analysis of the best value to use for each group of subsamples. These depth-bounds values are then used to shade each group and the results are blended together.(通过分组和prepass的方式,先通过prepass计算深度和法向量,分析后为每个组保留一个最好的值,最后计算并混合)
如何优化(移动端优化技术):
移动GPU的渲染
IMR-Immediate Mode Rendering:立即处理每个提交的渲染请求。
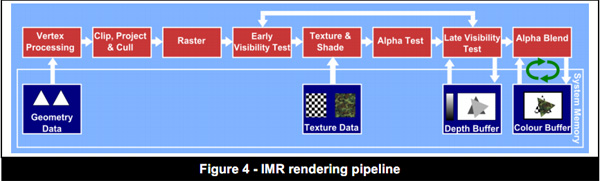
TBR-Tile Based Rendering:对渲染的画面进行分块,每个分块可以独立的计算,在低端机上时减少每个分块中片元的数量
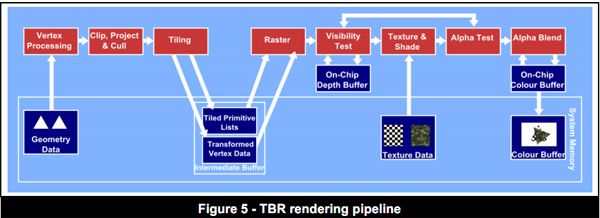


TBDR-Tile Based Deferred Rendering:对比上一个方法增加了隐藏面的剔除,减少了面数
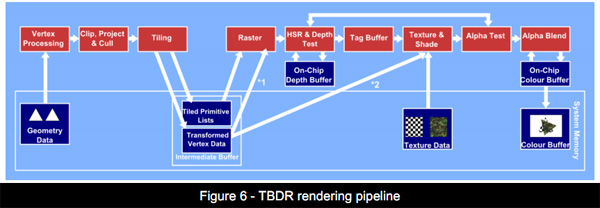
TBDR
FrameData和FrameBuffer
FrameDate又名arguments buffer(powervr),又名plolygon lists(arm),类似于上边所学的G-buffer中的数据。在IOS的powervr使用硬件ISR对FrameData进行处理
优化
- 及时清空FrameBuffer来提高性能。
- 避免在一帧的渲染中频繁切换(避免频繁的读取和绘制)。
- 在处理FrameDate之前,安卓机使用EarlyZ来剔除像素,但可能造成CPU的压力。IOS不需要EarlyZ,ISR硬件自动处理整剔除过程。
- MSAA和Blending在实际使用时效率很高,透明测试AlphaTest却导致在其之后的剔除被取消,增加了渲染量。powervr推荐的渲染顺序为Opaque、alpha-test、blending。
- 使用FrameBuffer中的数据时,可能会存在一些延迟。
- 顶点数量的增加在移动端GPU中造成DrawCall的增加,进而导致FrameDate数据的增加,超出内存的存储范围后会转存到其他位置,导致读写速度的下降。
- 避免gpu上的copy-on-write,否则会造成FrameData的累积,触发上一条的瓶颈。
- 移动端后处理的blit操作占用了很多FrameData空间和带宽。
- 在帧率不稳定的游戏中开启垂直同步,可能导致GPU更长时间的绘制等待。
- depth buffer在32位深度下效果最好。
- Mipmap的使用虽然增加了内存占用,但同时也提高了Cache命中率,减少了内存访问和带宽占用
- 移动端占用带宽对内存进行访问是极其耗电的操作,应当尽量避免,增加对Cache的访问。
- FrameTime(帧时间)的减少和优化在高帧率是效果显著的,低帧率是却效果不明显。
- DrawCall的优化是对CPU调度的优化。
- 性能瓶颈的排查,设置极小的framebuffer排查像素处理瓶颈,设置极小的贴图排查带宽瓶颈。



